
Appearance
Transformer模型
1.Transformer总体结构
Transformer的结构出自于《Attention is all you need》中所配的Transformer结构图。Transformer 模型依赖于两个独立、较小的模型:编码器和解码器。
编码器接收输入,而解码器输出预测。(解码器是用来做生成的) ![]()
在编码器-解码器架构出现之前,序列问题的预测完全基于对输入序列的累积记忆,这些记忆被“压缩”为一个隐藏状态的表示。尽管 LSTM 和 GRU 等架构试图改善长程依赖问题,但它们并没有完全解决 RNN 的根本问题,即无法完全通过预测来承载长序列的信息。
在编码器-解码器架构中,编码器接收整个输入序列。它将其转换为矢量化表示,其中包含每个时间步骤中输入序列的累积记忆。然后,输入序列的整个矢量化表示被输入到解码器中,解码器“解码”编码器收集的信息并尝试做出有效预测。
2.编码器
2.1 编码器原理
Transformer像Seq2seq一样的形式,具有Encoder-Decoder结构。
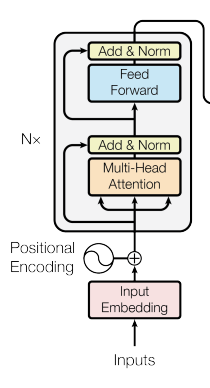
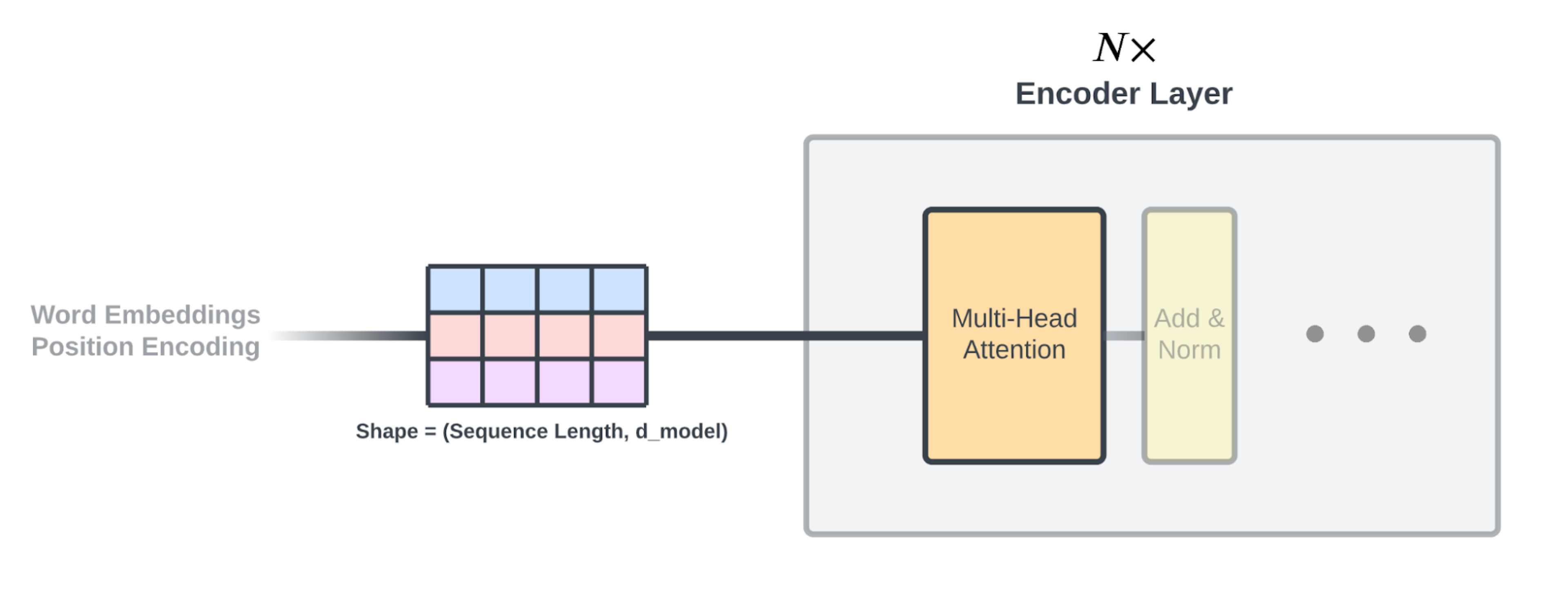
编码器负责将输入序列转换为机器可读的表示,这个过程会捕获单词之间的相似性及其在序列中的相对位置。输入序列首先经过输入嵌入和位置编码层。这些操作是为了输入的单词转换为适合编码器层处理的形式。
编码器层(也就是上面灰色的部分)是编码器的核心,大部分“魔法”都发生在这里。
在原始论文中,建议将编码器层的N设置为6,也就是堆叠六次。编码器由一个多头注意力块组成,后面跟着一个前馈神经网络,该神经网络在两个输出后都有残差连接和层规范化。
多头注意力模块能够发现单词之间的复杂关系,并确定每个单词对输入序列含义的贡献。这使得编码器能够像人类一样理解语言。
在编码器层之后,前馈网络会进一步转换输入序列,为下一个编码器层做准备。编码过程完成后,编码器获得的累积知识(最后一个编码器层的输出)将传递给解码器,解码器会利用这些知识生成最终的输出序列。
因此,TransformerEncoder由以下三个主要部分组成:
Embedding层(将单词ID序列转换为单词的分布表示)
Positional Encoding层
由任意N层堆叠的TransformerEncoderBlock层,包括Multihead Attention和FeedForward Network(每层都应用Add & Norm)
2.2 代码实现
python
import torch
from torch import nn
from torch.nn import LayerNorm
# 引入模块中的其他自定义类
from .Embedding import Embedding
from .FFN import FFN
from .MultiHeadAttention import MultiHeadAttention
from .PositionalEncoding import AddPositionalEncoding
class TransformerEncoderLayer(nn.Module):
# Transformer编码器层的初始化方法
def __init__(
self,
d_model: int, # 模型的维度
d_ff: int, # _feed-forward网络的维度
heads_num: int, # 多头注意力中头的数量
dropout_rate: float, # dropout率
layer_norm_eps: float, # LayerNorm的epsilon值
) -> None:
super().__init__() # 调用基类的初始化方法
# 初始化多头注意力层
self.multi_head_attention = MultiHeadAttention(d_model, heads_num)
# 初始化self-attention的dropout层
self.dropout_self_attention = nn.Dropout(dropout_rate)
# 初始化self-attention的LayerNorm
self.layer_norm_self_attention = LayerNorm(d_model, eps=layer_norm_eps)
# 初始化_feed-forward网络
self.ffn = FFN(d_model, d_ff)
# 初始化_ffn的dropout层
self.dropout_ffn = nn.Dropout(dropout_rate)
# 初始化_ffn的LayerNorm
self.layer_norm_ffn = LayerNorm(d_model, eps=layer_norm_eps)
# 前向传播方法
def forward(self, x: torch.Tensor, mask: torch.Tensor = None) -> torch.Tensor:
# 进行self-attention操作,并将结果加上原始输入x
x = self.layer_norm_self_attention(self.__self_attention_block(x, mask) + x)
# 进行_feed-forward操作,并将结果加上self-attention的结果
x = self.layer_norm_ffn(self.__feed_forward_block(x) + x)
return x
# 自定义的self-attention块
def __self_attention_block(self, x: torch.Tensor, mask: torch.Tensor) -> torch.Tensor:
# 多头注意力操作
x = self.multi_head_attention(x, x, x, mask)
# 对多头注意力的结果进行dropout操作
return self.dropout_self_attention(x)
# 自定义的_feed-forward块
def __feed_forward_block(self, x: torch.Tensor) -> torch.Tensor:
# 通过_feed-forward网络
return self.dropout_ffn(self.ffn(x))
class TransformerEncoder(nn.Module):
# Transformer编码器的初始化方法
def __init__(
self,
vocab_size: int, # 词汇表的大小
max_len: int, # 输入序列的最大长度
pad_idx: int, # padding的索引
d_model: int, # 模型的维度
N: int, # 编码器层的数量
d_ff: int, # _feed-forward网络的维度
heads_num: int, # 多头注意力中头的数量
dropout_rate: float, # dropout率
layer_norm_eps: float, # LayerNorm的epsilon值
device: torch.device = torch.device("cpu"), # 指定设备,默认为CPU
) -> None:
super().__init__() # 调用基类的初始化方法
# 初始化词嵌入层
self.embedding = Embedding(vocab_size, d_model, pad_idx)
# 初始化位置编码层
self.positional_encoding = AddPositionalEncoding(d_model, max_len, device)
# 初始化Transformer编码器层的列表
encodelayerList = [TransformerEncoderLayer(d_model, d_ff, heads_num, dropout_rate, layer_norm_eps) for _ in range(N)] # 创建N层编码器层
self.encoder_layers = nn.ModuleList(encodelayerList)
# 编码器的前向传播方法
def forward(self, x: torch.Tensor, mask: torch.Tensor = None) -> torch.Tensor:
# 将输入x通过词嵌入层
x = self.embedding(x)
# 将位置编码加到词嵌入的结果上
x = self.positional_encoding(x)
# 遍历所有编码器层,并进行前向传播
for encoder_layer in self.encoder_layers:
x = encoder_layer(x, mask)
return x3.解码器
3.1 解码器原理
解码器接收编码器的输出,这是编码器已经理解好了的知识。
在第一个预测时间步,解码器设置“句子开头”标记,这有助于解码器理解输入的文本是一个新的句子。
解码器根据已有的预测知识进行分析,得出初步的见解。然后,解码器将这些初步的见解与编码器的输出相结合,进行更深入的处理和分析。最后,解码器输出下一个时间步骤的预测,即所选单词成为输出序列中下一个单词的概率。
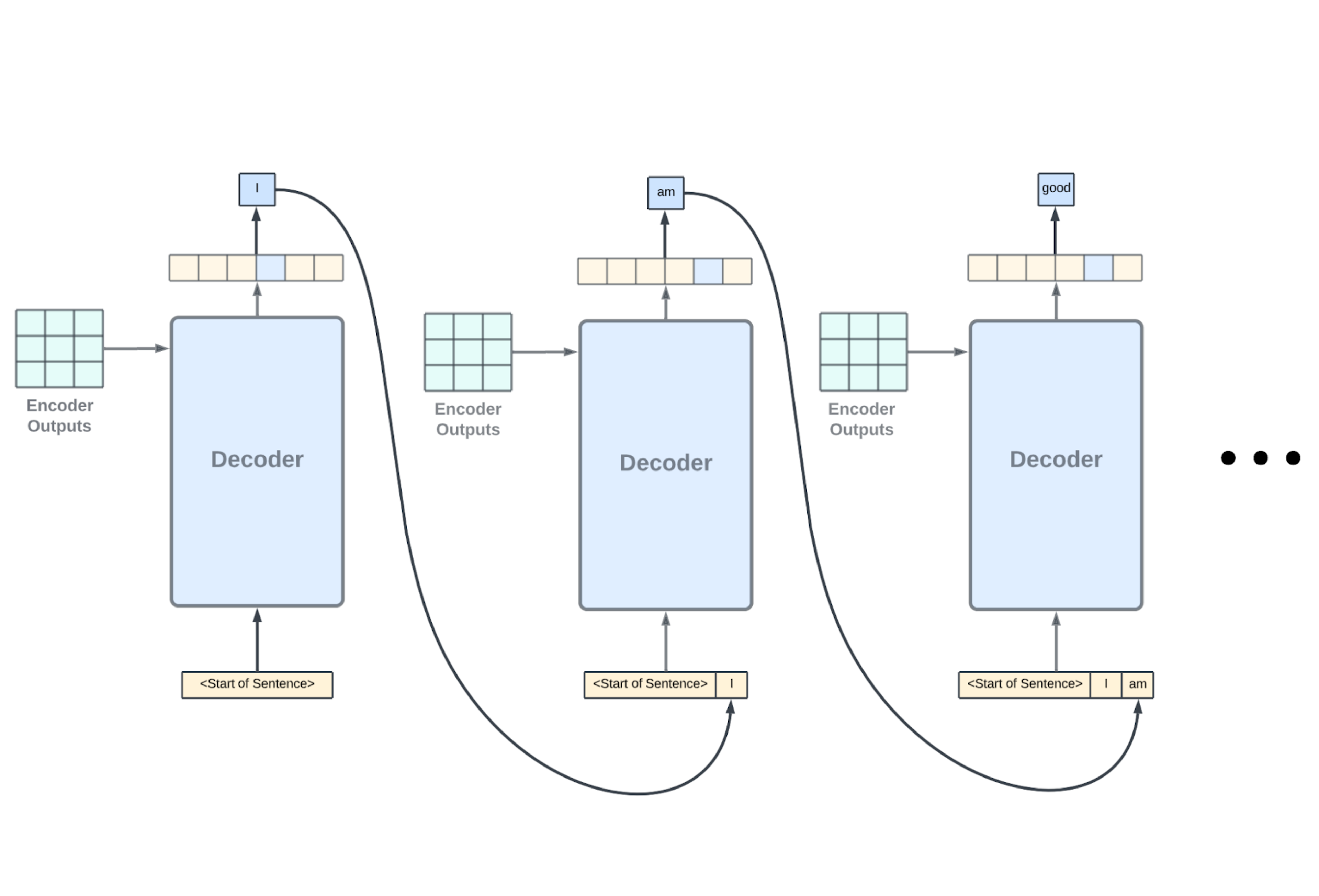
Decoder与Encoder一样,由Embedding、Positional Encoding、Multihead Attention、FeedForward Network组成。
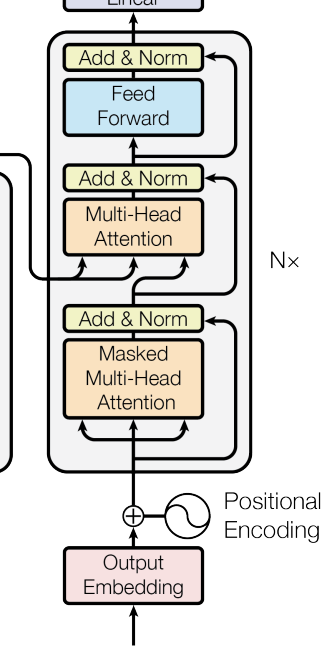
3.2 代码实现
python
import torch
from torch import nn
from torch.nn import LayerNorm
# 引入模块中的其他自定义类
from .Embedding import Embedding
from .FFN import FFN
from .MultiHeadAttention import MultiHeadAttention
from .PositionalEncoding import AddPositionalEncoding
class TransformerDecoderLayer(nn.Module):
# Transformer解码器层的初始化方法
def __init__(
self,
d_model: int, # 模型的维度
d_ff: int, # 馈前网络(Feed-Forward Network)的维度
heads_num: int, # 多头注意力中头的数量
dropout_rate: float, # dropout率
layer_norm_eps: float, # LayerNorm的epsilon值
):
super().__init__() # 调用基类的初始化方法
# 初始化目标自身的多头注意力层
self.self_attention = MultiHeadAttention(d_model, heads_num)
# 初始化目标自身注意力的dropout层
self.dropout_self_attention = nn.Dropout(dropout_rate)
# 初始化目标自身注意力的LayerNorm
self.layer_norm_self_attention = LayerNorm(d_model, eps=layer_norm_eps)
# 初始化源-目标的多头注意力层
self.src_tgt_attention = MultiHeadAttention(d_model, heads_num)
# 初始化源-目标注意力的dropout层
self.dropout_src_tgt_attention = nn.Dropout(dropout_rate)
# 初始化源-目标注意力的LayerNorm
self.layer_norm_src_tgt_attention = LayerNorm(d_model, eps=layer_norm_eps)
# 初始化馈前网络
self.ffn = FFN(d_model, d_ff)
# 初始化馈前网络的dropout层
self.dropout_ffn = nn.Dropout(dropout_rate)
# 初始化馈前网络的LayerNorm
self.layer_norm_ffn = LayerNorm(d_model, eps=layer_norm_eps)
# 解码器层的前向传播方法
def forward(
self,
tgt: torch.Tensor, # 解码器的输入
src: torch.Tensor, # 编码器的输出
mask_src_tgt: torch.Tensor, # 源-目标注意力的掩码
mask_self: torch.Tensor, # 目标自身注意力的掩码
) -> torch.Tensor:
# 目标自身注意力操作
tgt = self.layer_norm_self_attention(
tgt + self.__self_attention_block(tgt, mask_self)
)
# 源-目标注意力操作
x = self.layer_norm_src_tgt_attention(
tgt + self.__src_tgt_attention_block(src, tgt, mask_src_tgt)
)
# 馈前网络操作
x = self.layer_norm_ffn(x + self.__feed_forward_block(x))
return x
# 自定义的源-目标注意力块
def __src_tgt_attention_block(
self, src: torch.Tensor, tgt: torch.Tensor, mask: torch.Tensor
) -> torch.Tensor:
# 源-目标注意力操作,使用编码器的输出作为键和值
return self.dropout_src_tgt_attention(
self.src_tgt_attention(tgt, src, src, mask)
)
# 自定义的目标自身注意力块
def __self_attention_block(
self, x: torch.Tensor, mask: torch.Tensor
) -> torch.Tensor:
# 目标自身注意力操作
return self.dropout_self_attention(self.self_attention(x, x, x, mask))
# 自定义的馈前网络块
def __feed_forward_block(self, x: torch.Tensor) -> torch.Tensor:
# 馈前网络操作
return self.dropout_ffn(self.ffn(x))
class TransformerDecoder(nn.Module):
# Transformer解码器的初始化方法
def __init__(
self,
tgt_vocab_size: int, # 目标词汇表的大小
max_len: int, # 输入序列的最大长度
pad_idx: int, # 填充索引
d_model: int, # 模型的维度
N: int, # 解码器层的数量
d_ff: int, # 馈前网络的维度
heads_num: int, # 多头注意力中头的数量
dropout_rate: float, # dropout率
layer_norm_eps: float, # LayerNorm的epsilon值
device: torch.device = torch.device("cpu"), # 指定设备,默认为CPU
) -> None:
super().__init__() # 调用基类的初始化方法
# 初始化词嵌入层
self.embedding = Embedding(tgt_vocab_size, d_model, pad_idx)
# 初始化位置编码层
self.positional_encoding = AddPositionalEncoding(d_model, max_len, device)
# 初始化解码器层的列表
decodeLayerList = [
TransformerDecoderLayer(
d_model, d_ff, heads_num, dropout_rate, layer_norm_eps
)
for _ in range(N) # 创建N层解码器层
]
self.decoder_layers = nn.ModuleList(decodeLayerList)
# 解码器的前向传播方法
def forward(
self,
tgt: torch.Tensor, # 解码器的输入
src: torch.Tensor, # 编码器的输出
mask_src_tgt: torch.Tensor, # 源-目标注意力的掩码
mask_self: torch.Tensor, # 目标自身注意力的掩码
) -> torch.Tensor:
# 将解码器的输入tgt通过词嵌入层
tgt = self.embedding(tgt)
# 将位置编码加到词嵌入的结果上
tgt = self.positional_encoding(tgt)
# 遍历所有解码器层,并进行前向传播
for decoder_layer in self.decoder_layers:
tgt = decoder_layer(
tgt,
src,
mask_src_tgt,
mask_self,
)
return tgt4.注意力机制
4.1 注意力机制原理
注意力或全局注意力通常是自然语言处理模型取得成功的最重要因素之一。
注意力的基本思想是:模型可以根据输入词与上下文的相关性,更关注某些输入词。换句话说,模型为每个输入词分配不同程度的“注意力”,越重要的词获得的关注越多。
比如在“我的狗有黑色、厚厚的皮毛,性格活泼。我还有一只棕色皮毛的猫。我的狗是什么品种的?”这个例子中,没有注意力模型会同等对待猫和狗信息,可能导致错误答案,而有注意力,训练后的语言模型会减少对“棕色皮毛”的关注,因其与问题无关,这种有选择关注重要单词的能力有助于提高自然语言处理模型性能。
自注意力机制类似于搜索引擎,查询就像您在搜索栏中输入的搜索查询,K键就像数据库中网站的标题,V值就像网站本身。当您输入搜索查询时,系统会将其与数据库中的键进行比较,并根据键与查询的相似程度对值进行排名。
理解自注意力如何分配 注意力值 一个有用方法:将输入序列的每个元素与序列中的其他元素进行比较来构建相关矩阵。
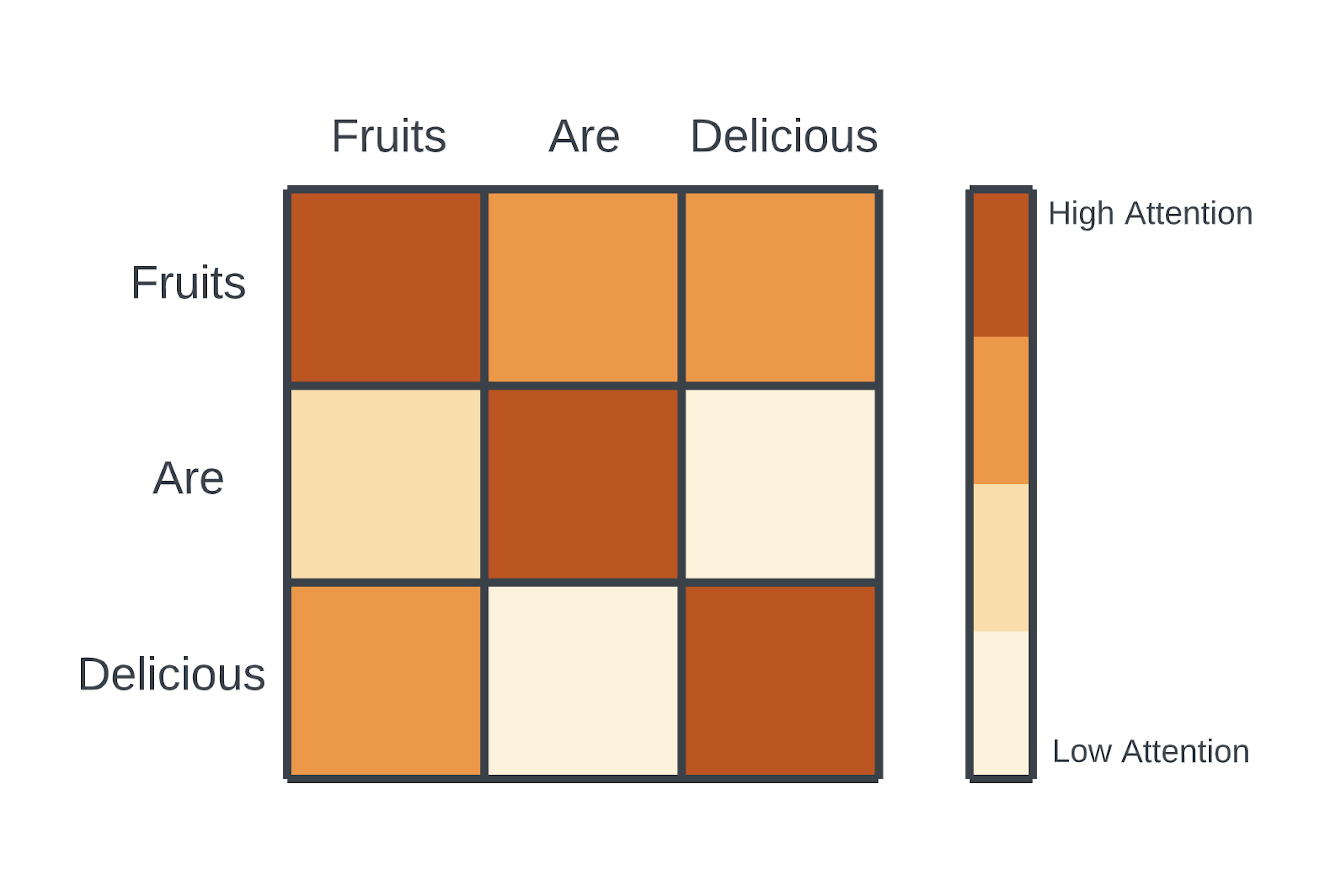
自注意力机制由三个部分组成:Q查询、K键和V值。每个单词的向量化表示被投影到三个较小的向量中,分别表示单词的Q查询、K键和V值。
4.2 注意力机制背后的数学原理
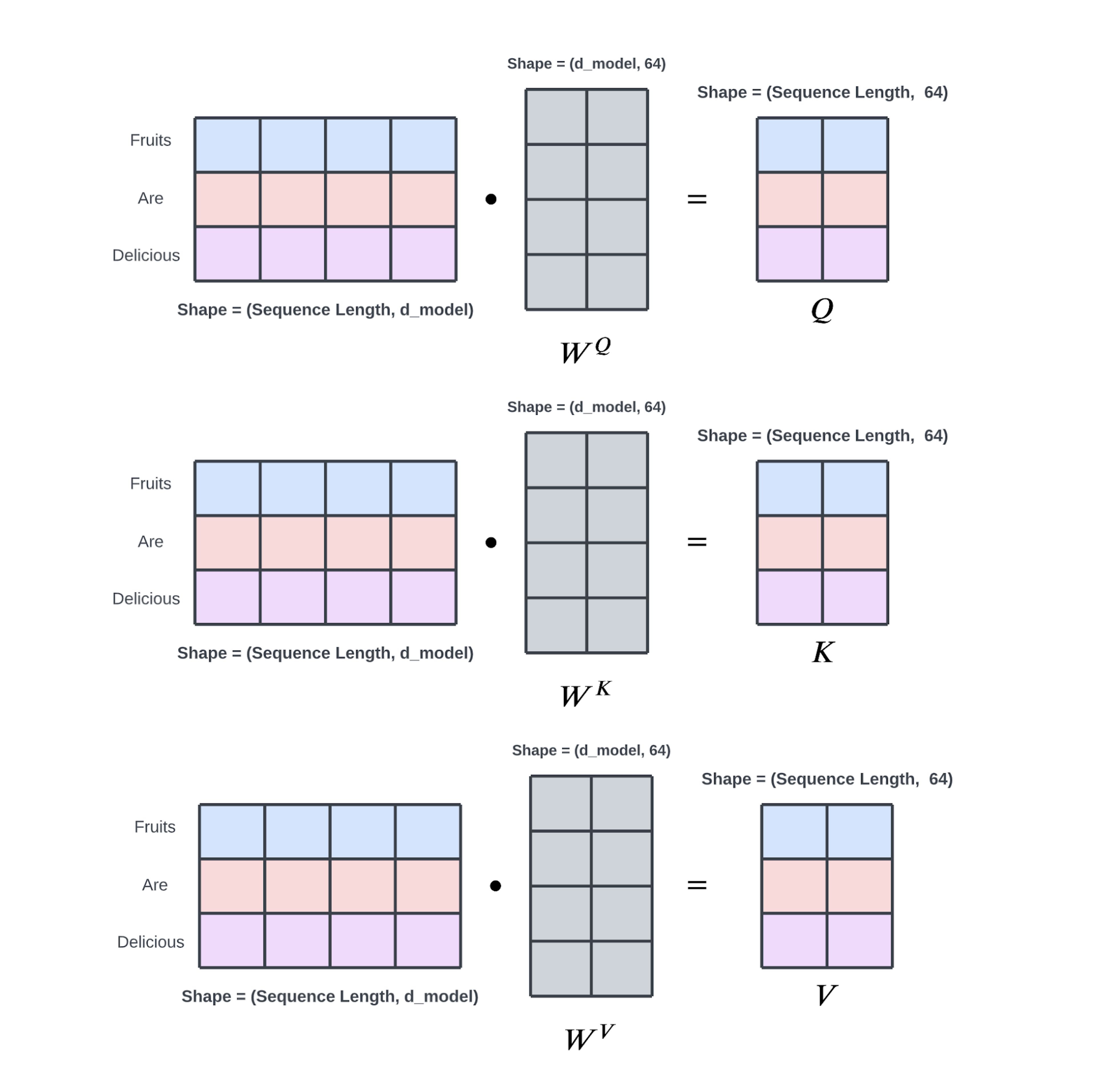
回想一下,位置编码的输出形状为 (序列长度),其中 dmodel 可以解释为嵌入维度。此矩阵是编码器层的输入。对于第一个编码器层之后的编码器层,它们的输入将是前一个编码器层的输出。
输入矩阵通过三个单独的权重矩阵线性投影到三个较小的矩阵中,即 Q查询、K键 和 V值。
这些矩阵的形状为(序列长度:64),其中维度 64 是论文作者选择的任意值。
Q查询、K键和V值的权重矩阵分别和这些权重矩阵与整个模型一起通过反向传播进行训练。为矩阵维度选择的值 64 不会影响自注意力的计算。
在Transformer中,采用了一种称为ScaledDotProductAttention的方法来计算注意力权重,该方法通过计算查询Q和输入k的点积来计算 注意力权重。在下一节中,我们将详细看看这个方法。
5.缩放点积注意力(Scaled Dot-Product Attention)
5.1 缩放点积注意力原理
Transformer 采用一种名为“Scaled Dot-Product Attention(缩放点积注意力)” 的自注意力机制。全局注意力考虑每个单词相对于整个输入序列的重要性,而自注意力则解读序列中单词之间的依赖关系。
例如,在“我去商店买了很多水果和一些家具。它们的味道很棒”这句话中,人类读者会推断“他们”指的是水果,而不是家具。使用全局注意力的模型可能会为“水果”、“家具”和“很棒”分配更高的注意力值,而无需理解这些词之间的关系。相比之下,自注意力将输入序列中的每个单词与其他每个单词进行比较,能够发现“他们”的本意。
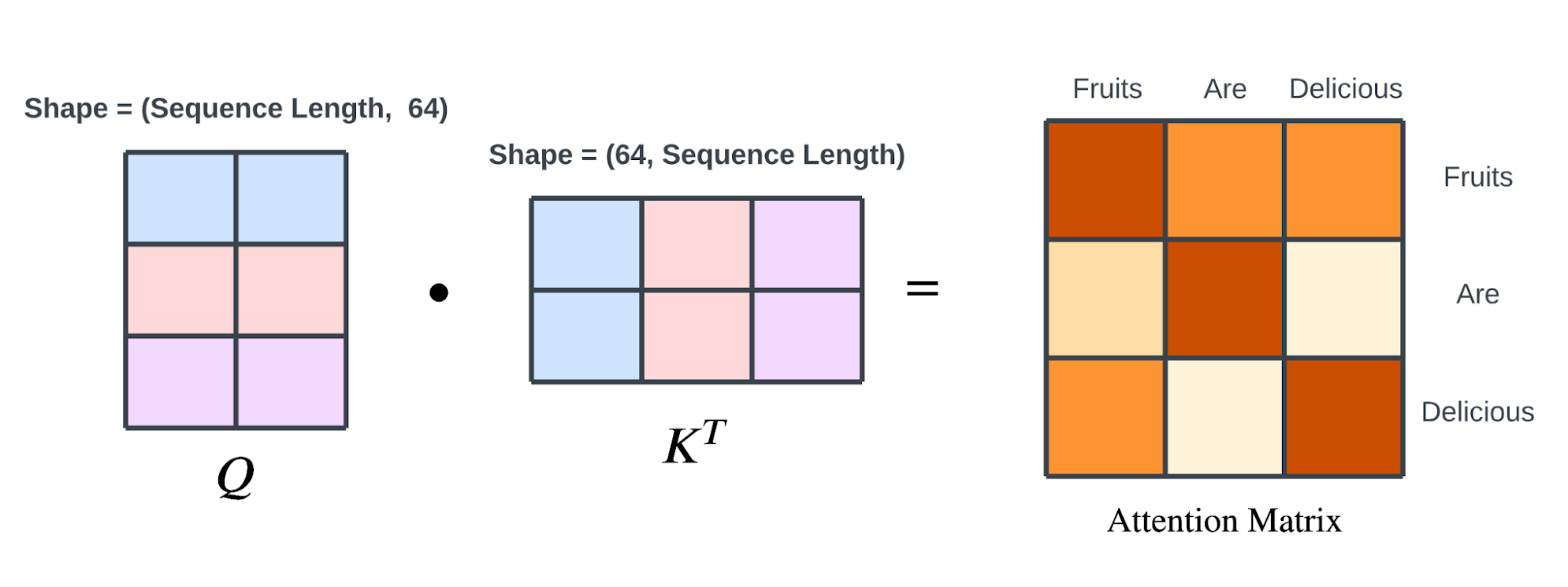
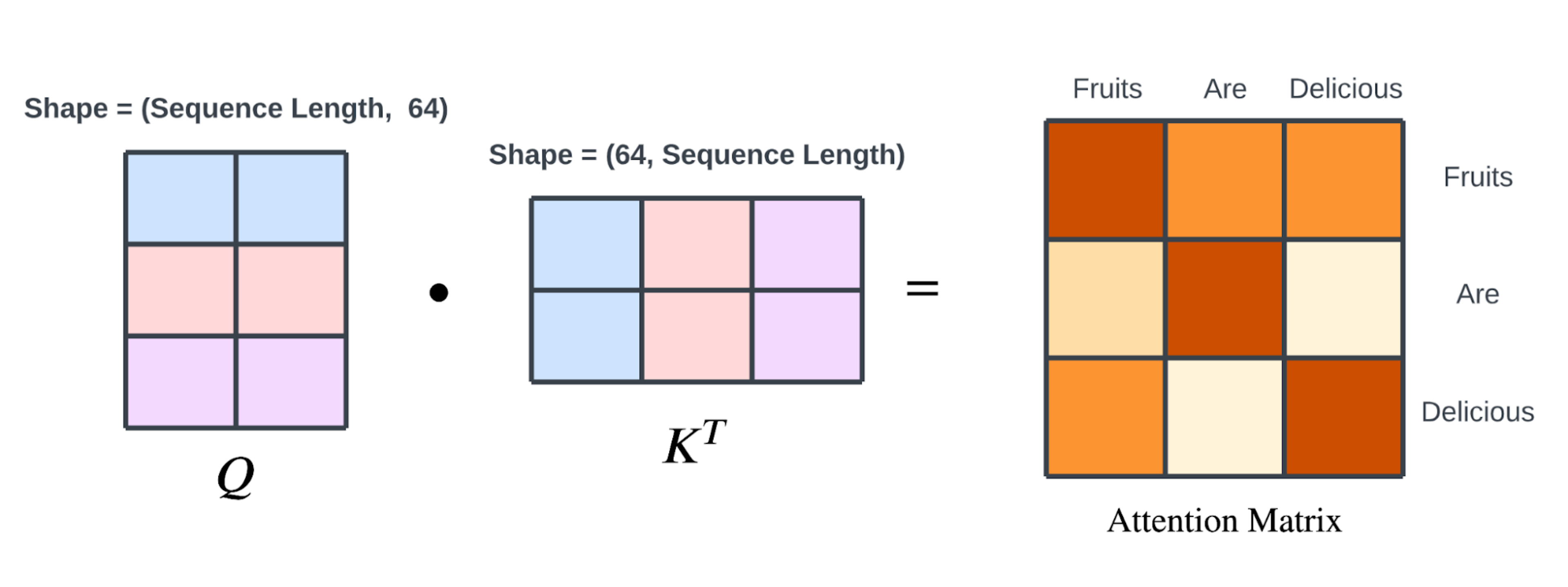
Q查询矩阵 对应的是 Q查询 中单词的矢量化表示,K键矩阵 对应的是 K键 中单词的矢量化表示,所以: Q X K = 权重矩阵 即如下图:
二维空间中两个向量之间的点积可以看作是向量之间余弦相似度的度量,由其量级的乘积缩放。
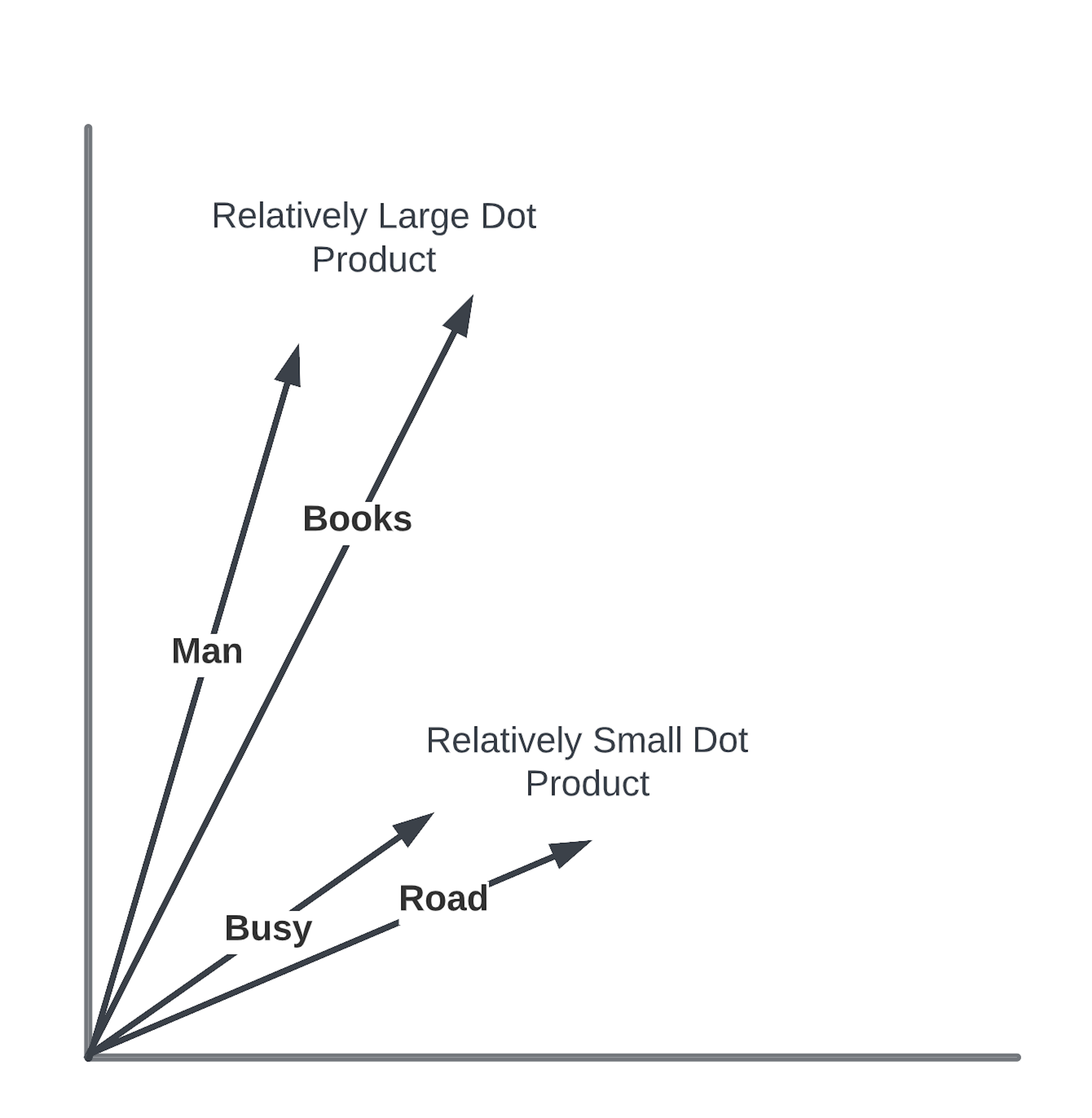
比如,有一个句子:“一个男人走在繁忙的道路上,手里拿着他刚买的几本书。”
我们想要理解这个句子中哪些词对于理解句子的整体含义是最重要的。
1.词向量表示:将句子中的每个词转换成一个向量。在这个简化的例子中,我们假设每个词的向量是二维的。
2.选择查询词:我们选择一个词作为“查询”(Q),比如“男人”,我们想要知道这个词在句子中与其他词的关系。
3.计算相似度:将“男人”的向量与句子中其他词的向量(这里我们把它们当作“键”K)进行比较,比如“书”和“道路”。通过计算向量间的点积来评估它们之间的相似度。
4.应用注意力权重:根据点积的结果,我们给每个词分配一个权重。如果“男人”和“书”的点积很高,意味着它们之间有很强的关联,因此“书”会得到一个较大的权重。
5.简化决策:在这个例子中,我们简化了决策过程,认为“男人”和“书”之间的关系比“男人”和“道路”之间的关系更重要,因为“书”直接描述了“男人”的行为。
6.最终输出:通过加权这些关系,我们可以得到一个综合的表示,这个表示强调了“男人”和“书”之间的关系,而对“男人”和“道路”的关系给予较少的重视。
通过这种方式,注意力机制帮助我们识别和强调句子中最重要的部分,忽略那些可能不那么关键的信息。在这个例子中,它帮助我们集中关注“男人”和“书”,因为它们对于理解句子可能更为重要。
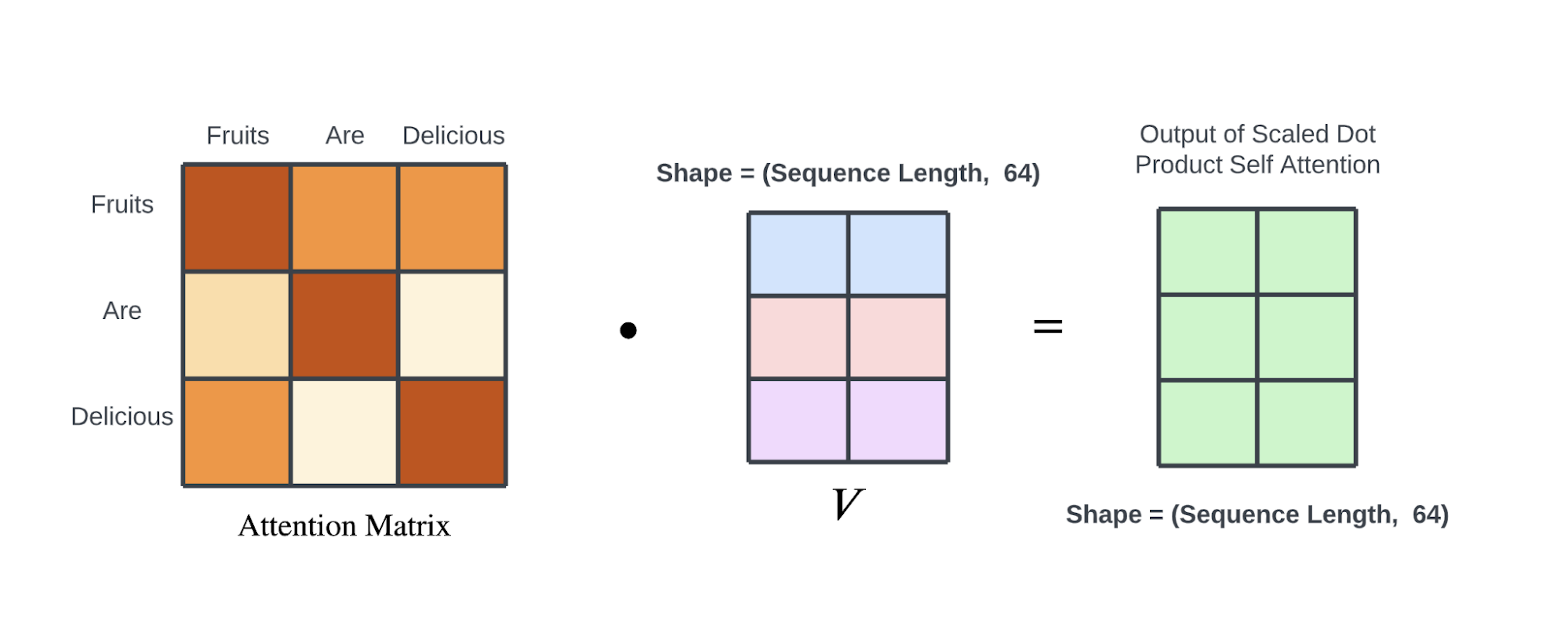
由 Q查询 和 K键 矩阵的点积生成的 注意力权重矩阵 具有 (序列长度,序列长度) 的形状。
注意力权重矩阵 中的每个值都除以 K键、Q查询 和 V值 矩阵大小的平方根(在本例中为 8)。
此步骤用于在训练期间稳定梯度。然后,注意力权重矩阵 通过 softmax 函数,该函数将其值标准化为 0 到 1 之间,并确保矩阵中每行的值总和为 1。
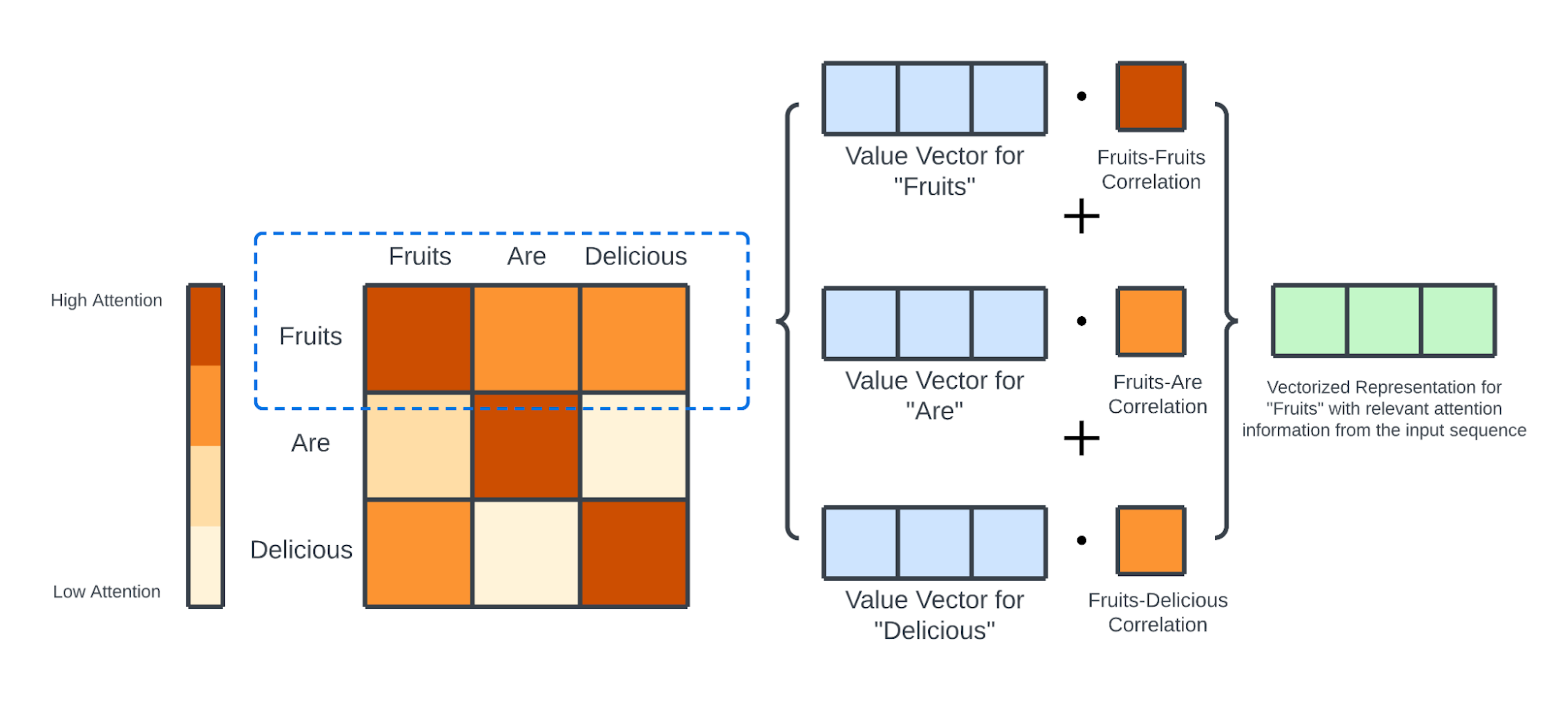
如前所述,使用 注意力值 和 值 向量进行加权求和。将注意力得分归一化为总和为 1 使得这种加权求和运算成为可能。
最后,将归一化的 注意力权重矩阵 与 值矩阵 相加,得到一个大小为 (序列长度,64) 的矩阵,该矩阵可以看作是带有注意力信息的输入序列的较小矢量化表示。
输出矩阵的第一行是V值矩阵中行向量的加权和,权重是输入序列中第一个词对所有其他词的注意力值。
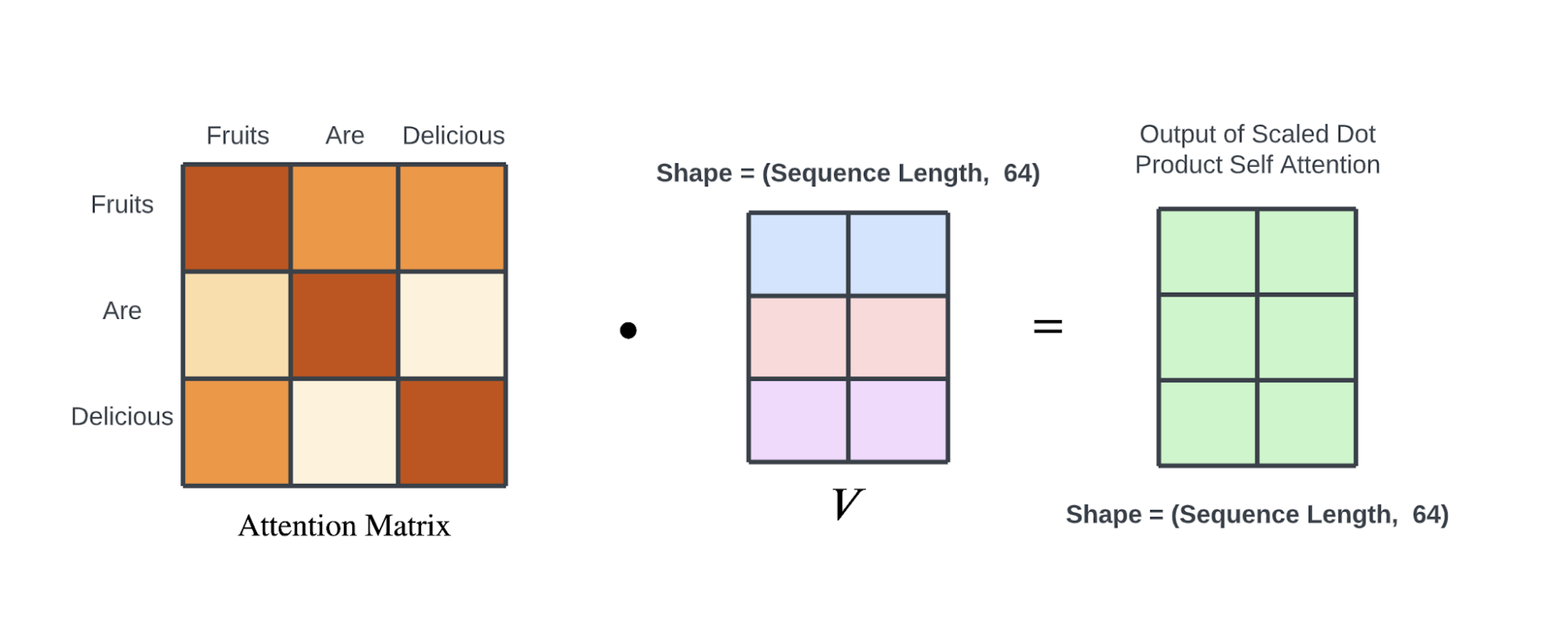
请注意,输出矩阵的大小为 (序列长度,64) 而不是 (序列长度,512)。
重点要记住,输出矩阵的大小应与原始词嵌入相同,因为它将用作下一个编码器层的输入,在第一个编码层的情况下,该编码器层需要将词嵌入作为输入。
在Transformer中使用的缩放点积注意力权重计算,可以使用查询 和输入 以下的公式表示。
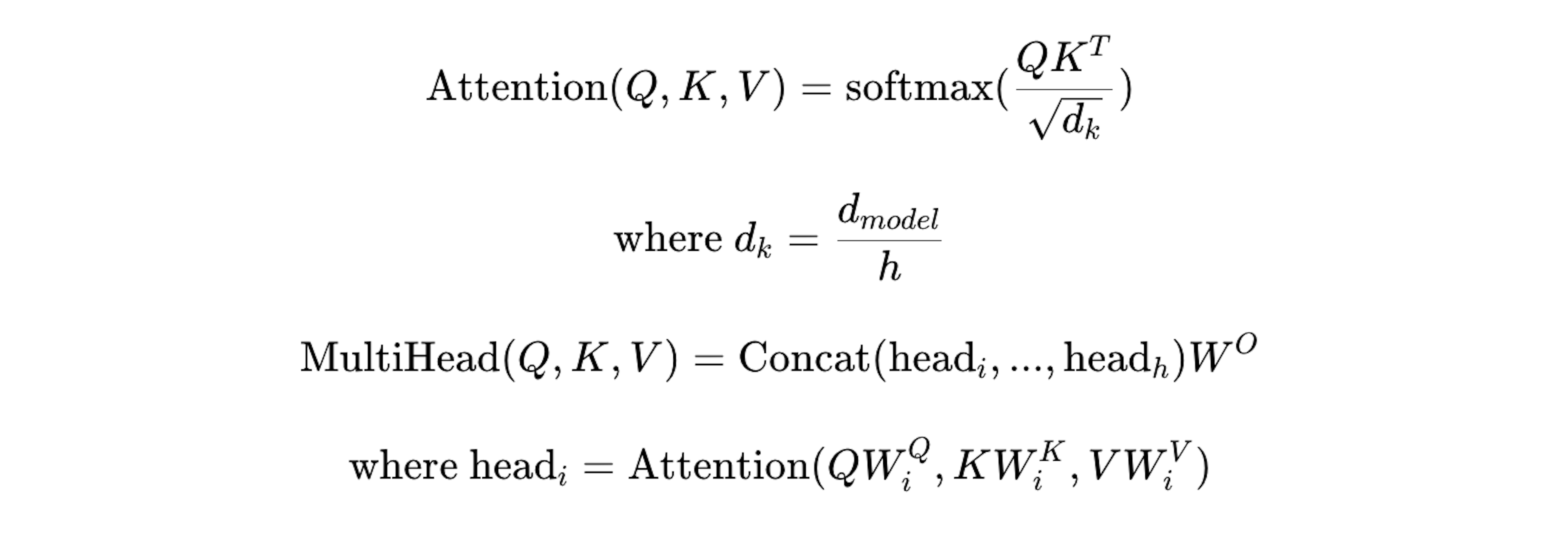
在处理问答或机器翻译等任务时,使用Transformer模型,上述公式中的 和 分别是表示文章数据的矩阵。
当处理的数据是 “用 D 维词向量表示的N个词的文章数据” 时,Q 和 K是 N*D大小的矩阵。
因此,这个计算了 查询 Q 和 输入数据 K 中的点积。
向量之间的点积大意味着方向接近,即向量之间的相似性高(词之间的相似性高)。也就是说,如果将文章数据输入到ScaledDotProductAttention 中,Q和K中的词之间的相似性将作为输入的重要性进行加权。
通过计算上面得到的注意力权重。该权重 和 值V的乘积,可以得到最终的输出注意力特征。
python
2.7.2 代码实现
import numpy as np
import torch
from torch import nn
class ScaledDotProductAttention(nn.Module):
# 初始化ScaledDotProductAttention类,它是一个PyTorch模型模块
def __init__(self, d_k: int) -> None:
super().__init__() # 调用基类的初始化方法
self.d_k = d_k # d_k是输入特征的维度,用于计算缩放因子
def forward(
self,
q: torch.Tensor, # 查询(Q),一个张量
k: torch.Tensor, # 键(K),一个张量
v: torch.Tensor, # 值(V),一个张量
mask: torch.Tensor = None, # 掩码,用于在计算注意力权重时忽略某些位置,默认为None
) -> torch.Tensor: # 定义forward方法,返回注意力机制的输出
scalar = np.sqrt(self.d_k) # 根据d_k计算缩放因子
# 计算Q和K的点积,然后除以缩放因子,得到未归一化的注意力权重
attention_weight = torch.matmul(q, torch.transpose(k, 1, 2)) / scalar
# 如果提供了掩码,则在计算注意力权重时将掩码位置的权重置为负无穷
if mask is not None:
if mask.dim() != attention_weight.dim():
raise ValueError(
"掩码的维度与注意力权重的维度不匹配,掩码的维度={}, 注意力权重的维度={}".format(
mask.dim(), attention_weight.dim()
)
)
attention_weight = attention_weight.data.masked_fill_(
mask, -torch.finfo(torch.float).max
)
# 对未归一化的注意力权重应用softmax函数,得到归一化的注意力权重
attention_weight = nn.functional.softmax(attention_weight, dim=2)
# 计算加权的值,即用归一化的注意力权重乘以V,完成注意力机制的计算
return torch.matmul(attention_weight, v)如果掩码的维度不等于注意力权重的维度,将引发错误。
注意力权重通过softmax函数计算得出:
python
attention_weight = nn.functional.softmax(attention_weight, dim=2) # 计算注意力权重最终,通过注意力权重和 输入X 的乘积得到加权结果:
python
return torch.matmul(attention_weight, v) # 通过 (注意力权重) * X 进行加权。6.多头注意力机制
6.1 多头注意力机制
在第上一节中,我们解释了Transformer模型使用Scaled Dot-Product Attention作为其注意力计算方法。
然而,Transformer中使用的注意力不仅仅是简单的Scaled Dot-Product Attention,实际上,Transformer采用了一种称为Multihead Attention的机制,它并行地执行多个Scaled Dot-Product Attention。
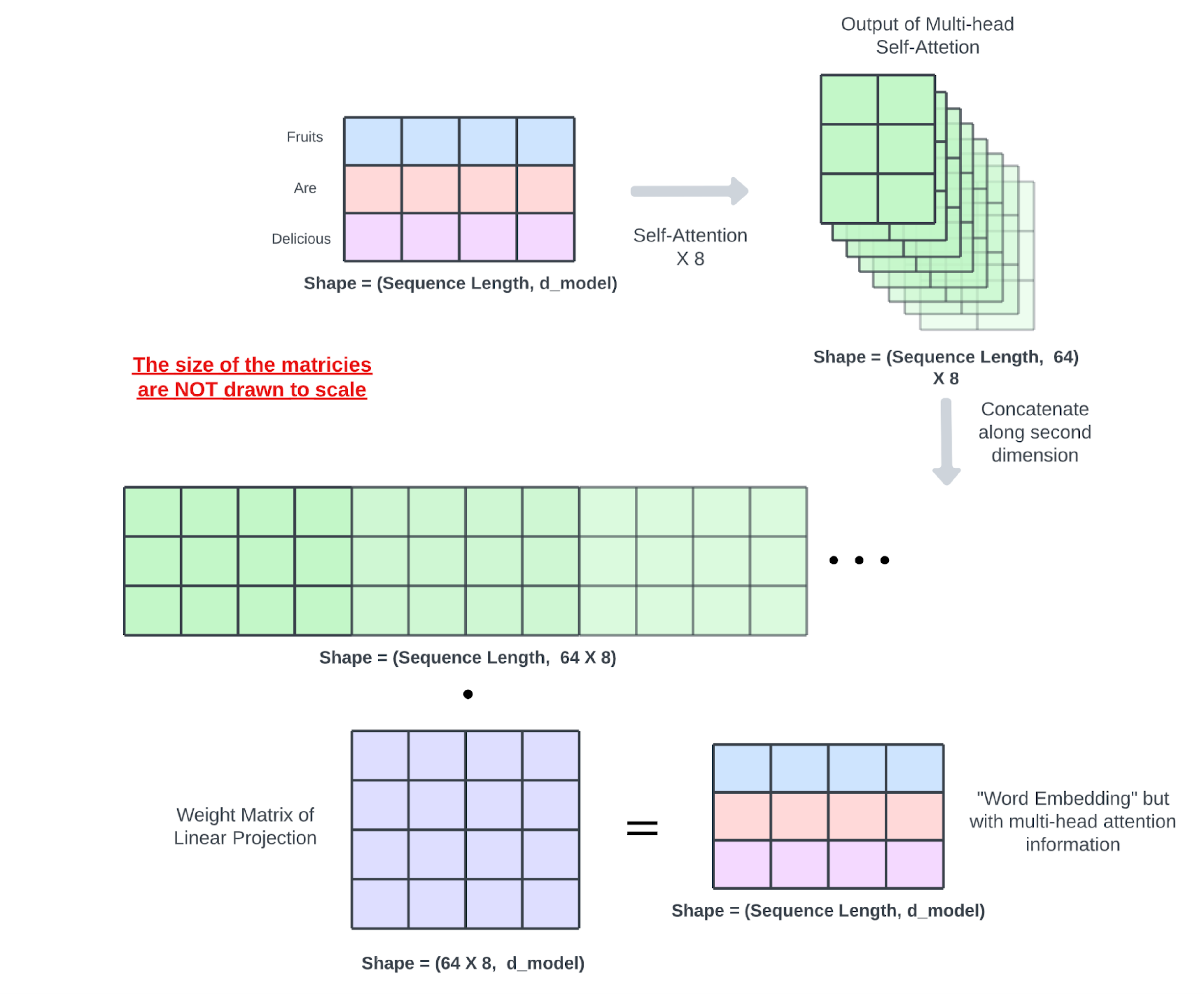
多头自注意力机制顾名思义就是将多个“注意力头”应用于同一序列。确切的自注意力机制会并行地对同一输入序列重新应用八次。对于每个注意力头,其Q查询、K键和V值权重矩阵 都会随机初始化,期间每个注意力头都能从输入序列中捕获不同类型的信息。
每个注意力头都会产生一个形状为 (序列长度,64) 的矩阵;然后它们沿其第二维连接起来,创建一个形状为 (序列长度,8*64) 的矩阵。在此矩阵上执行线性投影以“结合”所有注意力头的知识。用于线性投影的权重矩阵与模型的其余部分一起通过反向传播进行训练。
让我们来看一下论文中Multihead Attention的示意图。
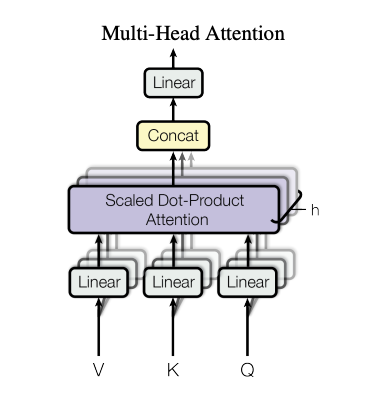
在 Transformer 的原始论文中,作者使用了 8 个注意力头。但后来的研究表明,这可能没有必要。在论文《分析多头自注意力:专用注意力头承担重任,其余部分可以修剪》中,Elena Voita 等人提出,在 8 个注意力头中,有三个“专用”注意力头承担了大部分工作。具体来说,这些专用注意力头的作用被假设如下:
图中的 h(头数) 表示并行运行的 ScaledDotProductAttention 的数量。
python
2.8.2 代码实现
import torch
from layers.transformer.ScaledDotProductAttention import ScaledDotProductAttention
from torch import nn
class MultiHeadAttention(nn.Module):
def __init__(self, d_model: int, h: int) -> None:
super().__init__()
self.d_model = d_model
self.h = h
self.d_k = d_model // h
self.d_v = d_model // h
# 定义参数矩阵
self.W_k = nn.Parameter(
torch.Tensor(h, d_model, self.d_k) # 头数, 输入维度, 输出维度(=输入维度/头数)
)
self.W_q = nn.Parameter(
torch.Tensor(h, d_model, self.d_k) # 头数, 输入维度, 输出维度(=输入维度/头数)
)
self.W_v = nn.Parameter(
torch.Tensor(h, d_model, self.d_v) # 头数, 输入维度, 输出维度(=输入维度/头数)
)
self.scaled_dot_product_attention = ScaledDotProductAttention(self.d_k)
self.linear = nn.Linear(h * self.d_v, d_model)
def forward(
self,
q: torch.Tensor,
k: torch.Tensor,
v: torch.Tensor,
mask_3d: torch.Tensor = None,
) -> torch.Tensor:
batch_size, seq_len = q.size(0), q.size(1)
# 按头数重复Query, Key, Value
q = q.repeat(self.h, 1, 1, 1) # head, batch_size, seq_len, d_model
k = k.repeat(self.h, 1, 1, 1) # head, batch_size, seq_len, d_model
v = v.repeat(self.h, 1, 1, 1) # head, batch_size, seq_len, d_model
# 在缩放点积注意力之前进行线性变换
q = torch.einsum(
"hijk,hkl->hijl", (q, self.W_q)
) # head, batch_size, d_k, seq_len
k = torch.einsum(
"hijk,hkl->hijl", (k, self.W_k)
) # head, batch_size, d_k, seq_len
v = torch.einsum(
"hijk,hkl->hijl", (v, self.W_v)
) # head, batch_size, d_k, seq_len
# 分割头
q = q.view(self.h * batch_size, seq_len, self.d_k)
k = k.view(self.h * batch_size, seq_len, self.d_k)
v = v.view(self.h * batch_size, seq_len, self.d_v)
if mask_3d is not None:
mask_3d = mask_3d.repeat(self.h, 1, 1)
# 缩放点积注意力
attention_output = self.scaled_dot_product_attention(
q, k, v, mask_3d
) # (head*batch_size, seq_len, d_model)
attention_output = torch.chunk(attention_output, self.h, dim=0)
attention_output = torch.cat(attention_output, dim=2)
# 在缩放点积注意力之后进行线性变换
output = self.linear(attention_output)
return output